Cos’è robots.txt e come funziona questo file?
Il file robots.txt contiene istruzioni per i bot e gli spider che dicono loro a quali pagine internet possono accedere ed eseguire scansione e a quali non accedere. Il file robots.txt è molto rilevante per i motori di ricerca in generale e il motore di ricerca in Google in particolare e il suo uso aiuterà il motore di ricerca a capire quali pagine volete scansionare nel vostro sito e quali pagine non saranno scansionate. Nell’articolo parleremo del file robots, del suo uso e la sua importanza per la promozione organica. Ma prima è importante capire cos’è il file robots.txt?
Cos’è robots.txt?
Il file robots.txt è un gruppo di disposizioni per gli spider e i bot. Questo file è compreso nei file di origine che si trovano nella maggior parte dei siti internet. I file robots.txt sono destinati soprattutto alla gestione di operazioni di bot che hanno buone intenzioni (come motori di ricerca), ma non sono programmati per influenzare bot dannosi che non ascoltano le istruzioni nel file. Pensate al file robots.txt come a un codice di comportamento in palestra, parte ascolteranno le disposizioni e parte no.
Un bot è un software automatico che interagisce con i siti e le applicazioni. Ci sono bot buoni e bot cattivi, uno spider di motori di ricerca è un bot con buone intenzioni. Questo bot scansiona le pagine internet e le aggiunge all’indice affinché compaiano nei risultati della ricerca. Il file robots.txt aiuta a gestire le attività di questi scanner di internet, in modo che non sovraccarino il vostro server di archiviazione e impediscano un indice di pagine che non devono esservi (pagina di ringraziamento, politica di privacy ecc.)

Come funziona il file robots.txt?
Il file robots.txt è solo un file di testo senza codice HTML (e quindi il suo suffisso è txt). Il file robots è archiviato nel vostro server come ogni altro file nel sito ed è possibile visualizzarlo digitando l’URL del sito e aggiungendo robots.txt/. Per esempio: https://www.easyclouditalia.it/robots.txt
Il file non è collegato a nessun altro posto nel sito, e quindi non è probabile che qualcuno vi si imbatta a meno che scriva il suo URL preciso. La maggior parte dei bot spider dei motori di ricerca cercheranno di scansionare questo file prima degli altri file del sito. È importante specificare che se avete un sottodominio nel sito, questo deve avere il proprio file robots.txt. Per esempio: file separati https://www.cloudflare.com/robots.txt e https://blog.cloudflare.com/robots.txt.
Un file robots.txt fornisce istruzioni al bot ma non le può fare rispettare. Bot buoni dei motori di ricerca cercheranno di trovare il file quando arrivano al sito per operare secondo le istruzioni. Bot dannosi ignoreranno il file robots.txt o lo elaboreranno per trovare le pagine che avete definito di non scansionare nel sito. Gli spider che scansionano il file agiscono secondo le istruzioni più specifiche nel file, cosicché se contiene istruzioni contraddittorie, il bot che scansiona eseguirà l’istruzione più dettagliata.
Date un’occhiata al file robots.txt di Clodflare
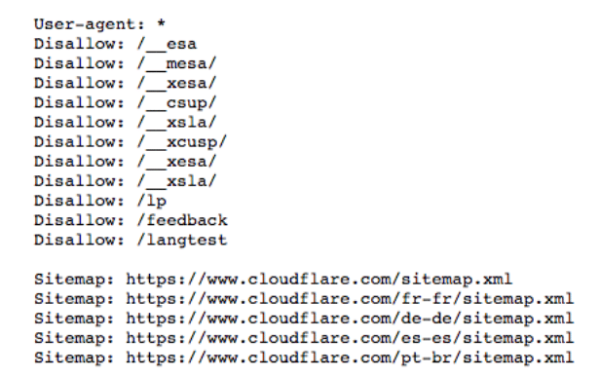
Protocolli e ordini nel file robots.txt
Un protocollo è un formato per dare istruzioni o comandi. File robots.txt usano alcuni protocolli diversi. Il protocollo principale si chiama Robots Exclusion, è il modo di dire ai bot quali pagine internet e risorse evitare. Nei siti di WordPress il protocollo principale è compreso nel file. Il secondo protocollo principale è il protocollo Sitemap. In questo protocollo, i file di Sitemap presentano ai robot quali pagine scansionare e questo aiuta ad assicurare che tutte le pagine rilevanti nel vostro sito siano scansionate.
Altre istruzioni nel file robots
1. User-agent
Rappresenta istruzioni di scansione per un robot specifico. In user-agent scriveremo il nome del robot che vogliamo che scansioni il sito. Si può consentire a tutti i bot di scansionare il sito contrassegnando un asterisco in user-agent. Questo comando è destinato a persone che vogliono che solo motori di ricerca specifici scansionino il loro sito.
Bot diffusi nei motori di ricerca che si possono digitare nel file robots.txt:
- Googlebot
- Googlebot-image (foto)
- Googlebot-news (notizie)
- Googlebot-video (filmati)
- Bingbot
- MSNbot-media (foto e filmati)
- Baiduspider
2. Disallow
Il comando più diffuso nel file robots. Il comando segnala ai bot di non scansionare una pagina, una cartella o gruppo di cartelle nel vostro sito o server. Non necessariamente è proibito vedere le pagine alle quali è applicato questo comando, semplicemente non sono rilevanti per i navigatori (come il pannello di gestione di WordPress – wp-admin). È possibile usare il comando Disallow in alcuni modi:
- Blocco di una pagina singola – il comando Disallow per una singola pagina internet viene eseguito quando si manda un file con il comando e dopo una pagina internet dal sito. Per esempio se si vuole bloccare la scansione dell’articolo Come fermare richieste spam nel modulo di contatto nei siti di WordPress:
Disallow: blog/security-blog/contact-form-spam-in-wordpress/ - Blocco di una cartella – a volte sarà più efficiente per voi bloccare una cartella di pagine dal sito anziché scrivere tutte le pagine separatamente. Per esempio:
Disallow: /_file/ - L’accesso è aperto a tutti – questo comando di fatto dice che robot e spider possono scansionare tutte le parti del sito. Il comando è:
Disallow: - Blocco di tutto il sito – è possibile con un unico comando nel file chiedere a tutti i motori di ricerca di bloccare tutte le pagine nel sito. Il comando è:
Disallow: /
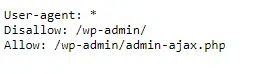
3. Allow
Il comando Allow è in pratica il comando opposto a Disallow. Il comando dice ai bot che sono autorizzati ad accedere a una pagina internet o libreria. Questo comando vi aiuta ad autorizzare bot a scansionare una pagina o cartella specifica mentre tutti gli altri ordini nel file sono definiti Disallow.
4. Crawl-delay
Questa operazione è destinata a ritardare la ricerca per indicizzazione dei bot per diminuire il carico dalle risorse della rete. L’operazione vi consente di indicare quanto tempo il robot di scansione deve aspettare fra richiesta e richiesta, in millesimi di secondo. Il motore di ricerca di Google non riconosce questa operazione, ma è possibile definirla direttamente per mezzo del Search Console.
5. Sitemap
Il protocollo della mappa del sito aiuta i bot a sapere cosa deve comprendere la loro scansione. Per digitare il protocollo nel file robot.txt dovete scrivere: Sitemaps: e dopo immettere la mappa del sito, che si può trovare in Google Search Console.
Come si crea un file robots.txt?
I 2 modi più efficienti per creare un file robots nel vostro sito sono a mano o per mezzo di uno strumento SEO. Per creare un file robots a mano dovete aprire un file di testo (WordPad) nel computer, digitare i comandi desiderati e dopo caricarlo sul server o per mezzo di un add-on. Fate attenzione che il nome del file rimanga robots.txt quando lo caricate e di caricare un solo file.
La creazione di un file robots.txt per mezzo di uno strumento di SEO è molto semplice. Per creare un file di questo tipo con lo strumento Yoast SEO cliccate su Yoast nel menu di WordPress, dopo cliccate su Modifica di file e infine cliccate sul pulsante Crea file robots.txt. Cliccando un pulsante il file è stato creato ed è stato caricato sul server. Per controllare se avete creato con successo un file robots per il sito potete controllare con lo strumento robots.txt Tester o aprire il file nel vostro browser con l’indirizzo del vostro dominio e dopo aggiungere /robots.txt all’URL
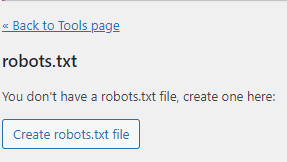
In conclusione
Il file robots.txt è quello che dice ai motori di ricerca a quali pagine accedere e a quali pagine non accedere. La conservazione della privacy di parte delle pagine nel sito e impedire la loro scansione è importante per SEO e per la promozione di siti perché ci sono pagine nel vostro sito che non devono comparire nella rete di ricerca e non c’è nessun motivo che i navigatori vi entrino. Le pagine più diffuse sono ovviamente le cartelle nel pannello di gestione (wp-admin), le pagine di ringraziamento, pagine prive di contenuto, la politica di privacy ed altre ancora.
Informazioni sull'autore
O Fialkov, 38, fondatore e CEO di Fialkov Digital, una società specializzata nelle pubblicità su Google e una varietà di canali. Specializzato nel marketing digitale, Fialkov tiene lezioni e laboratori sul marketing con l’ausilio strumenti avanzati, destinate a persone e aziende. Il proprietario di EasyCloud, una società che, grazie a Cloudways, rende il mondo del web hosting accessibile a tutti nel cloud. Attraverso le più grandi società del mondo di storage sul cloud con una comoda interfaccia, la massima sicurezza del sito web e un prezzo eccellente.

